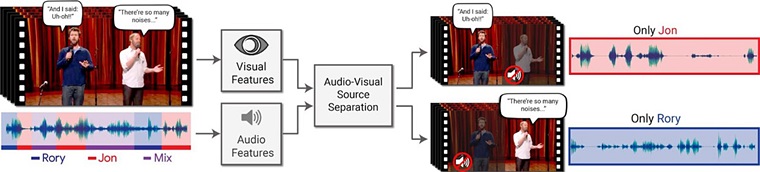
Nehéz még pontosan felmérni, hogy mi mindenre lesz használható a Google egy új, fejlesztés alatt lévő algoritmusa, de mindenképp izgalmas fejlesztésnek tűnik a tömeges zajból egy bizonyos beszélő szavait kiszűrni képes mesterséges intelligencia. A kutatásról
Nehéz még pontosan felmérni, hogy mi mindenre lesz használható a Google egy új, fejlesztés alatt lévő algoritmusa, de mindenképp izgalmas fejlesztésnek tűnik a tömeges zajból egy bizonyos beszélő szavait kiszűrni képes mesterséges intelligencia. A kutatásról A kiindulási pont az volt, hogy miközben az emberek egész jó hatásfokkal képesek kiszűrni, elkülöníteni és megérteni egy bizonyos beszélő által mondottakat akkor is, ha egyszerre többen beszélnek, a számítógépek egyelőre nem képesek erre. Ez pedig egyre növekvő problémát jelent napjainkban, amikor terjedőben vannak a különféle gépi asszisztensek.
A Google kutatói által kifejlesztett mélytanulásra képes algoritmus képes ennek a problémának a megoldására, mégpedig úgy, hogy a beszélő arcát figyeli, azaz vizuális jeleket társít a hangokhoz.
A szoftvermérnökök azzal kezdték a fejlesztést, hogy először egyes emberek önálló beszédének felismerésére tanították meg a rendszert, majd virtuális partit hoztak össze, amiben több beszélő is volt egyszerre, háttérzajokkal kiegészülve. Ebben a környezetben folytatták az AI képzését, ami az arcokra fókuszálva képessé vált az egyedi beszélőket elkülöníteni, és csak az ő hangsávjukat kiszűrni. Ez még akkor is egész jó hatásfokkal sikerült, ha a beszélő részben eltakarta arcát a kezével vagy mikrofonnal.